Het gebruikersgedrag op phishingsites analyseren via een API en R
Steeds vaker krijgen we phishingmails of spam binnen. Op het moment is zelfs 2/3e van al het mailverkeer met verkeerde intenties verstuurd 1! De links in de emails gaan naar frauduleuze websites die proberen je gegevens te stelen of je op te lichten door bijvoorbeeld bestelde artikelen niet te leveren.
Die schade proberen securitybedrijven – maar ook de overheid – te beperken door het opzetten van verschillende security awarenessprogramma’s om mensen voor te lichten over de gevaren van phishingsites en andere frauduleuze websites. Tijdens bijvoorbeeld een phishingsimulatie worden mails uitgestuurd naar een grote groep mensen om te kijken naar hun klik- en invulgedrag op de website die achter de link zit. Hierdoor kun je gemakkelijk meten hoe groot de groep is die in de praktijk zou worden opgelicht doordat zij bijvoorbeeld niet op de hoogte zijn hoe een phishingwebsite herkend kan worden. Uiteindelijk kom je dan op een dataset uit van het aantal kliks en het aantal verstuurde inloggegevens. Maar wat gebeurt er in de tussentijd op zo’n phishingwebsite? Zijn er bijvoorbeeld deelnemers die de website wel openen, maar vervolgens weer wegklikken? Of deelnemers die wel inloggegevens invoeren op de website, maar vervolgens besluiten deze niet te versturen? Er is nog vrij weinig bekend over het gedrag van gebruikers op phishingwebsite, daarom besloot ik hier in te duiken.
Om meer te weten over waarom mensen interacteren met phishingwebsite is het allereerst belangrijk om wat meer in de psychologie achter phishing te duiken. Hierbij komen drie hoofdredenen voorbij: een gebrek aan kennis, visuele deceptie en een gebrek aan aandacht. Er wordt massaal geklikt, omdat mensen ten eerste niet wéten hoe ze een dergelijke phishingaanval of -website kunnen herkennen. Doordat er te weinig (of geen) voorlichting is gegeven over het onderwerp, hebben mensen niet scherp op hun netvlies staan waar ze op moeten letten. Mocht dit wel al het geval zijn, dan kunnen zij alsnog in een phishingsite trappen doordat de phishingwebsite zó ontzettend op de legitieme versie van de website lijkt dat de basistraining in het herkennen van phishingwebsites niet voldoende is. Hierbij kan gedacht worden aan het gebruik van dezelfde logo’s en layouts, typosquatting 2, het gebruik van HTTPS of het overnemen van contactgegevens. Wanneer voorlichting op al voorgaande punten is gegeven kan alsnog iemand klikken door het gebrek aan aandacht. Wanneer je in de ochtend nog niet je kopje koffie hebt gehad of er de hele dag vervelende collega’s aan je bureau hebben gestaan, klik je soms achteloos op een linkje of log je toch ergens in.
Het gebrek aan voorlichting of aandacht is lastig in een experiment mee te nemen, maar het op het verkeerde spoor zetten van deelnemers door bijna exact dezelfde websites te gebruiken is daarentegen vrij gemakkelijk. Bij het meten van het gedrag op phishingsites moet natuurlijk eerst gekeken worden wat gedrag nu eigenlijk is en of dit gedrag afwijkt van legitieme websites. Daardoor is een onderzoeksopzet gekozen waarbij er een legitieme website (1) en een phishingwebsite (2) worden bezocht door deelnemers. De phishingwebsite is in feite een kopie van de legitieme website waar later een aantal wijzigingen zijn aangebracht. Deze wijzigingen, ook wel heuristieken, zijn kenmerken die over de afgelopen jaren vaak zijn gevonden op phishingwebsites.
De heuristieken zijn in te delen in drie categorieën: verschillen in content, verschillen in content en URL en verschillen in content, URL en het gebruik van HTTPS. Bij verschillen in content kan gedacht worden aan typfouten, gebruik van andere afbeeldingen of het toevoegen van tijdsdruk of lagere prijzen. Wanneer daar een verschil in URL boven op komt, is de URL zó aangepast dat deze niet meer legitiem lijken en zijn. Daarbij zijn typosquattingdomeinnamen, het gebruik van verlopen domeinnamen (die niets met de inhoud te maken hebben) en het gebruik van IP-adressen veelvoorkomend. De laatste stap is het wel of niet gebruiken van HTTPS tegenover HTTP.
Twee websites werden ontwikkeld als onderzoeksopzet en zijn middels een enquête uitgezet bij deelnemers. De enquête vroeg naar wat algemene zaken zoals opleidingsniveau, leeftijd en ervaring met het kopen op internet. Daarnaast werd er gevraagd om per website een aantal vragen te beantwoorden, zoals ‘zou je op deze website bestellen?’ en werd er op het einde gevraagd of er verschillen tussen de twee websites was gezien. En zo ja, welke verschillen zijn dit dan? Halverwege het experiment werd de volgorde van de websites gewisseld, zodat gebruikers niet al de ‘geleerde’ kennis van de eerste, legitieme, website zouden gebruiken en daardoor de resultaten zouden beïnvloeden.
Door naar de websites: allereerst natuurlijk de legitieme versie. Hiervoor is de website ‘The Phone Store’ ontwikkeld, waarbij de nieuwste iPhones aangeschaft kunnen worden. Er is hierbij bewust gekozen voor een onbestaand merk (van de website, niet de telefoons), aangezien er anders eventuele merkassociatie kan ontstaan. De website bestaat uit verschillende pagina’s: de homepagina, een registratiepagina, een loginpagina, een winkelmandje en de pagina waar je op terecht komt als je de aanschaf succesvol hebt afgerond.
Bij de tweede website, de phishingwebsite, is eerst de legiteme website gekopieerd naar een nieuwe omgeving. Hierin zijn later de heuristieken in verwerkt. Op verschillende levels zijn de websites identitiek, zodat dit de resultaten niet verder beïnvloedt (zie ook wel de Visual Similarity Assessment Module). Uiteindelijk is gekozen voor een aantal aanpassingen binnen de content, een andere domeinnaam die phishy klinkt en de afwezigheid van een SSL certificaat. Dit leidde tot de volgende wijzigingen:
| Categorie | Onderdeel | Designkeuze |
|---|---|---|
| Content (1) | User Interface | Logo in lage resolutie |
| Tijd | Tijdsdruk, het verkoopt snel uit | |
| Taal | Spelfouten en verkeerde grammatica | |
| Chinese tekens in de footer | ||
| Valse security | Gebruik van niet-bestaande security logo’s | |
| Icoon van slotje in de tekst | ||
| Domeinnaam (2) | Domeinnaam | URL lijkt op phishing (.virusscannerpro.org.uk) |
| HTTPS (3) | SSL certificaat | Geen certificaat geinstalleerd |
Wanneer deze punten verwerkt zijn in de phishingsite, ziet dit er zo uit:
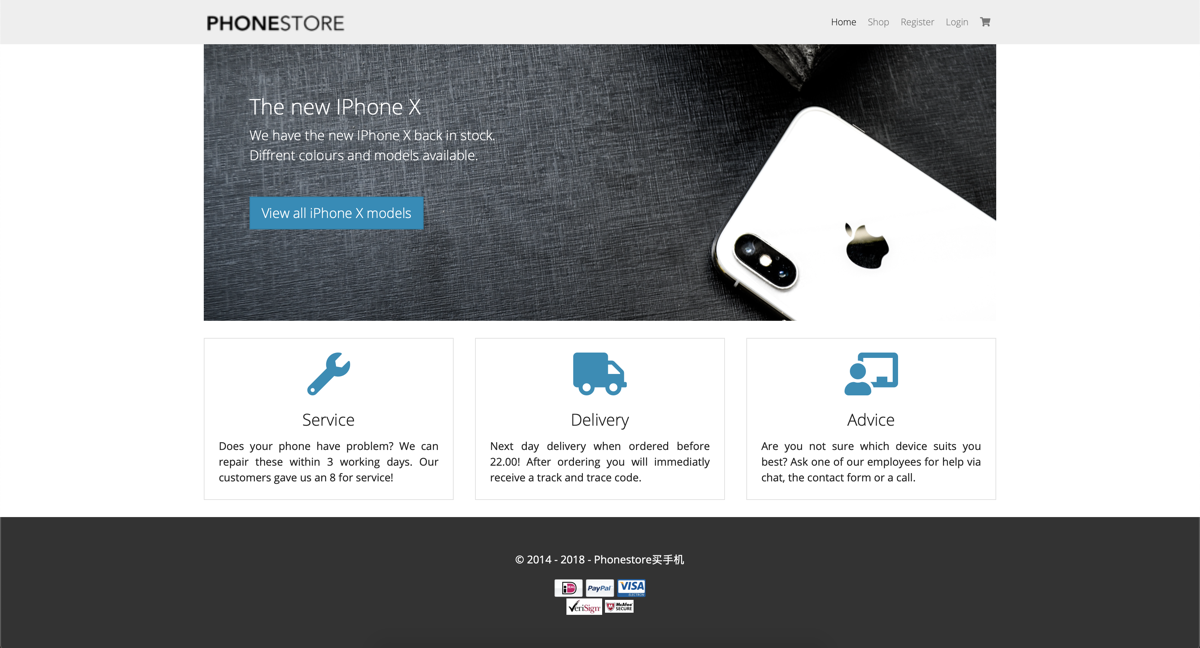
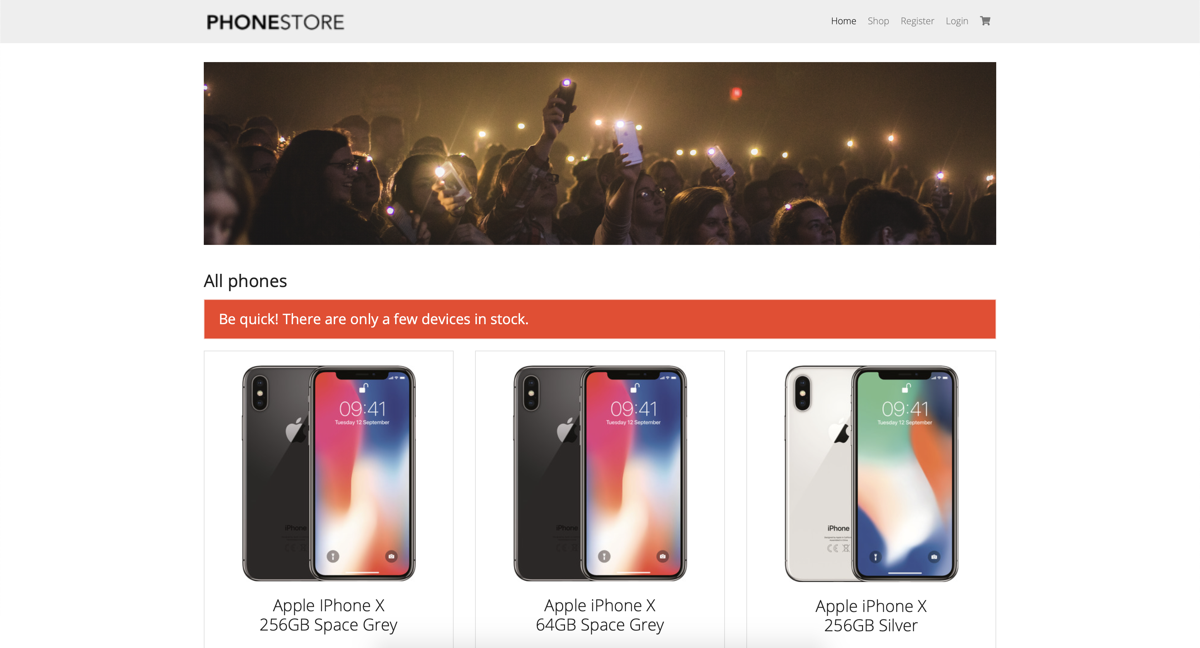
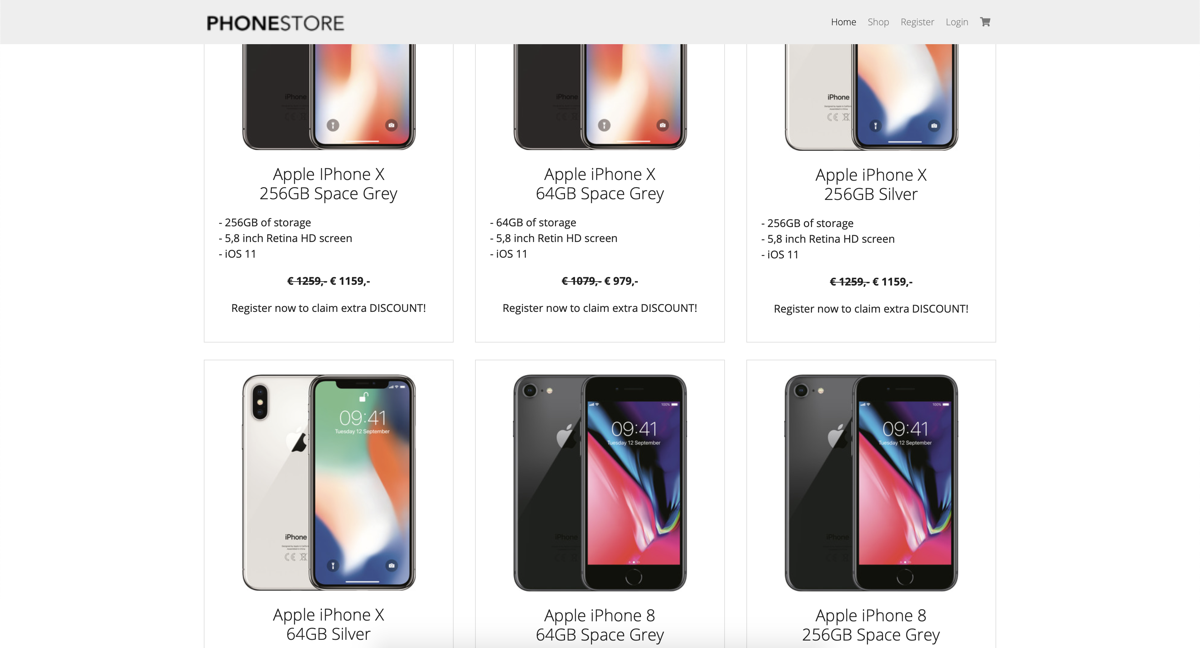
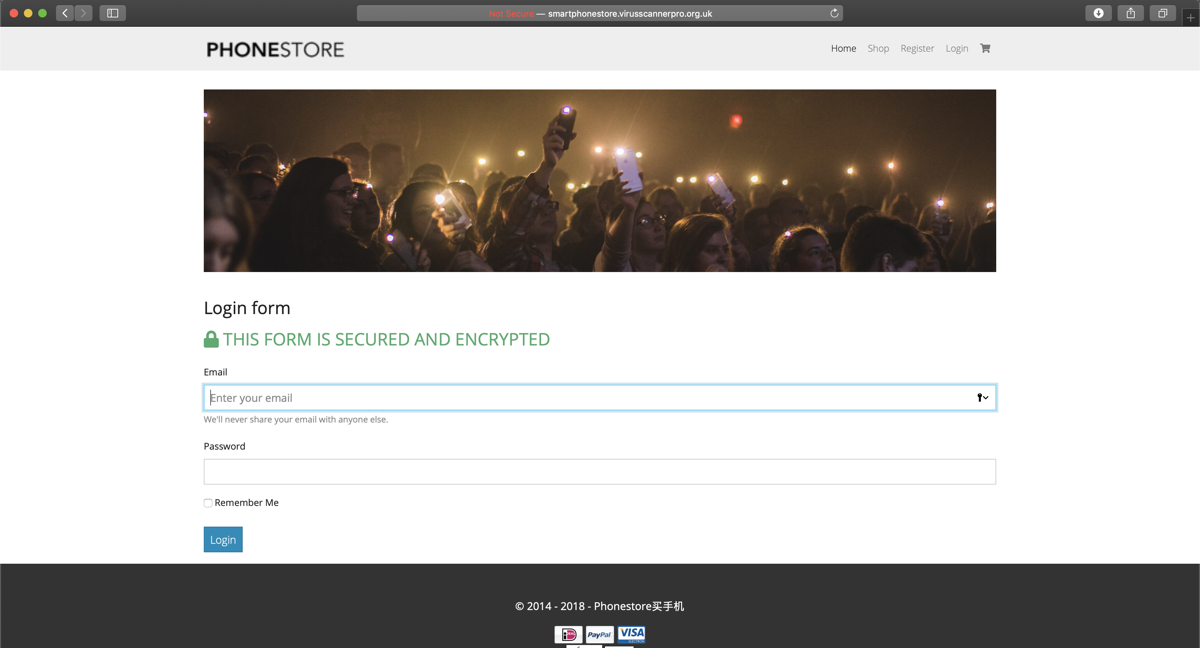
Deze twee websites vormen nu de basis voor de onderzoeksopzet. Vervolgens moet er natuurlijk gekeken worden naar wat gedrag is en hoe dit gemodelleerd kan worden op een website. Hier is al redelijk wat onderzoek naar gedaan gelukkig. Wel zijn deze bijna allemaal in het kader van user experience (UX). Niet iets wat direct vertaald kan worden naar security awareness dus. Daarentegen is er wel een onderzoek beschikbaar waarbij gekeken wordt naar het onderscheid tussen mensen op basis van gedrag gemeten door biometrie, nuttig voor onder andere continuous authentication 3. Deze eigenschappen worden dan ook als basis gebruikt voor het definiëren van gedrag en zijn als volgt:
- Snelheid van je muis op de website
- Het maximale bereik van je muisbewegingen
- Het aantal kliks en toetsaanslagen
- Tijd waarin je inactief bent op de site
Zelf heb ik nog wat eigenschappen toegevoegd welke het naar mijn mening iets vollediger maken. Sommige zijn voornamelijk voor de betrouwbaarheid voor het onderzoek (zoals de latency of minimal sample frequency). Persoonlijk denk ik dat de efficiëntie van deelnemers een rol kan spelen op beide websites. Efficiëntie is hoe efficiënt een deelnemer van punt A naar punt B binnen een website gaat. Deze A en B zijn beiden punten waar een deelnemer heeft geklikt op de pagina, bijvoorbeeld op een button of een link. Wanneer iemand heel efficiënt te werk is gegaan (efficiëntie dichtbij 1), zal het pad tussen punt A en punt B vrijwel recht zijn. In de praktijk is dit vaak niet zo, want mensen gaan op onderzoek uit op de website of scrollen naar beneden en boven. Dit afgelegde pad is dan ook wel het bewegingspad waarin mensen op onderzoek gaan (het ‘wanderen’ op een website). Nu kun je met deze gegevens efficiëntie op meerdere manieren berekenen. In dit onderzoek ben ik gegaan van de lengte tussen punt A en punt B (dus het kortste pad), gedeeld door het daadwerkelijke pad dat werd afgelegd met de muis tussen punt A en punt B. Samen met de totale tijd die een deelnemer op de website heeft gespendeerd zijn de eigenschappen voor dit onderzoek compleet.
Maar wat is er nodig om deze gegevens te verzamelen? Eigenlijk hoeft er niet eens zoveel opgeslagen te worden van de gebruiker, alles is namelijk te berekenen met de volgende variabelen:
- De coördinaten met bijbehorende tijd van de muis
- De kliks met bijbehorende tijd van muis
- De toetsaanslagen met bijbehorende tijd en in welk veld de toetsaanslag is gedaan
- De schermresolutie
Door het maken van een API (gehost op phishinganalytics.com, sounds not fishy at all, right?), worden deze gegevens opgeslagen in een database. De API maakt gebruik van Lumen, een microframework, en wordt getriggerd door JavaScript:
$(document).on("mousedown", function(e) {
// Post data
}
$(document).mousemove(function(e) {
// Post data
}
$(document).keypress(function(e) {
// Post data
}
Wanneer iemand de website laadt en dus een klik, beweging of toetsaanslag doet, wordt de functie getriggered en de informatie opgeslagen. Dit resulteert in redelijk wat records in de database. In onderstaand filmpje kun je zien hoe iemand de phishingvariant bezoekt, daar met de muis beweegt, klikt en inlogt.
Bij het enkel bezoeken van de pagina’s, te zien in de screencast, is al een klein bewegingspad gemaakt. Deze informatie kun je vrij gemakkelijk plotten en ziet er visueel uit zoals op onderstaande heatmap met muisbeweging als blauwe punten is geplot:
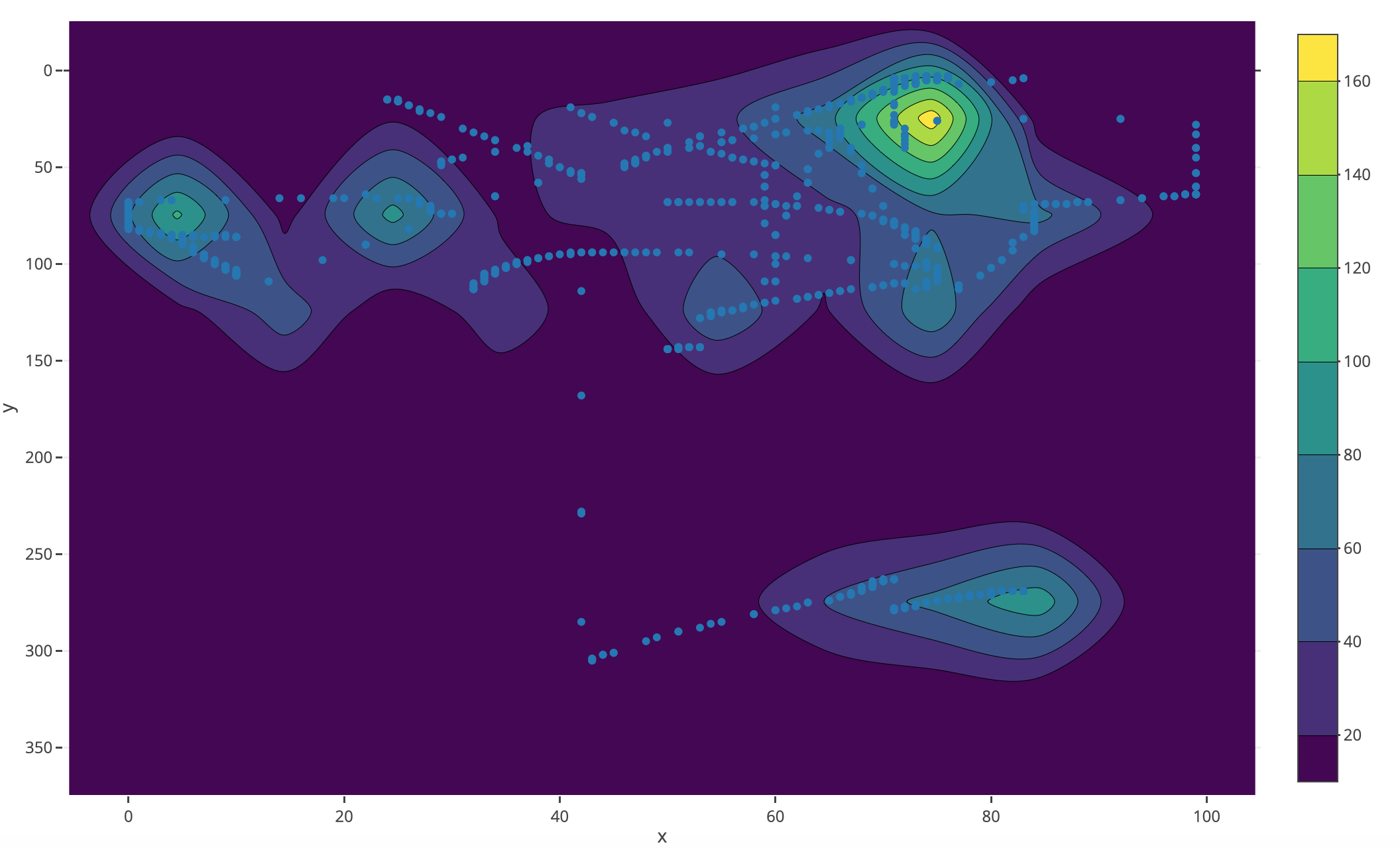
Dit screenshot representeert de gemeten coördinaten van de muis op de pagina. De X-as geeft hierbij de breedte van de webpagina op het scherm (dus maximaal 100%) aan, de Y-as de hoogte van de pagina. Dit is maximaal 350%, aangezien een pagina scrollbaar is. Hierdoor ga je dus verder dan de hoogte van je eigen scherm op de pagina. Iedere keer wanneer er iets berekend moest worden met coördinaten, zijn deze coördinaten genormaliseerd naar 1000 door de coördinaten te delen door de resolutie en vervolgens te vermenigvuldigen met 1000.
Met zulke heatmaps is het gemakkelijk inzicht te krijgen hoe bijvoorbeeld het maximale bereik van je muisbeweging werkt. Het maximale bereik is eigenlijk niets meer dan de maximale afstand tussen twee coördinaten op een webpagina. Nu kun je de afstand tussen ieder punt gaan berekenen en hiervan de hoogste pakken, maar dan ben je nog wel een tijdje bezig. Nu is convex hulling4 een techniek die veel wordt gebruikt binnen computer graphics waarbij je alle buitenste punten van een verzameling punten met elkaar verbindt. Hierdoor sluiten deze lijnen alle punten in. Wanneer je convex hulling toepast hoef je alleen lengte tussen de lijnen met de punten waar twee lijnen samenkomen te brute forcen. En dat scheelt je toch redelijk wat tijd, moeite en rekenkracht.
Dus check; op basis van de geplotte muiscoördinaten kan het maximale bereik per deelnemer berekend worden. Iets wat nu ook gemakkelijk berekend kan worden met de muiscoördinaten is de gemiddelde snelheid. Hiervoor heb ik even wat natuurkundekennis moeten afstoffen, maar je komt met √(y2 – y1)2 / (x2 – x1)2 al een heel end. Deel deze vervolgens door het tijdsverschil (t2 – t1). Herhaal deze stappen voor de minimale snelheid, de maximale snelheid en het gemiddelde en deze is ook check.
De kliks en aantal toetsaanslagen bereken je door per deelnemer de som van alle kliks en toetsaanslagen te nemen. Daarnaast moet de tijd van inactiviteit meegenomen worden. Dit is nog vrij lastig te berekenen, want wanneer weet je dat iemand inactief is? Van iedere deelnemer wordt de latency (gemiddelde tijd tussen laden website en beweging) opgeslagen. Op basis hiervan is een inschatting gemaakt van de tijdsrange waarin een beweging gedaan kan worden. Valt het buiten een range, dan wordt het meegeteld als inactieve tijd.
Nu alleen nog efficiëntie. Zoals eerder besproken is de efficiëntie van een gebruiker de mate waarin iemand zich aan het ideale pad heeft gehouden op een website. Als je efficiënt bent, volg je het pad van punt A naar punt B. In de praktijk komt dat bijna niet voor, je gaat toch wat meer onderzoekend over de pagina. Die efficiëntie kun je berekenen door de totale lengte tussen twee kliks (gebruikmakend van dezelfde middelbare-school-formule) te delen door de totale lengte van de beweging tussen de twee kliks. Hieruit komt een getal dat dicht bij de 0 ligt, meestal scroll je aardig wat af op een pagina.
Goed, combineer deze berekende gegevens in één dataset. Per website (legitiem of phishing) weet je wat de snelheid, aantal kliks, inactiviteit, bereik en efficiëntie was. Samen met de gegevens uit de enquête (die eerst worden gereformat naar bruikbare informatie) wordt de dataset opgebouwd. Woop woop, data! Deze data wordt gebruikt om analyses op uit te voeren. Zo worden verschillende variabelen tussen de legitieme site en de phishingsite tegen elkaar gezet en vergeleken. Hierbij wordt ANOVA gebruikt om te kijken of er statistische relevantie is.
Nu is het niet het doel om daadwerkelijk een grootschalig onderzoek te verrichten bij een grotere groep, maar te testen of de modellen werken en dit werkbaar is voor onderzoek naar gebruikersgedrag op websites. Uiteindelijk waren er 30 participanten die hebben meegewerkt, dus niet een aantal waar je erg waardevolle conclusies uit kan trekken. Toch vind ik het leuk om deze te delen. Wellicht dat met een grootschaliger onderzoek de conclusies kunnen worden onderstreept.
De belangrijkste bevinding hierbij is het verschil in efficiëntie op beide websites. Hierbij waren de deelnemers een stuk efficiënter in hun pad van punt A naar punt B op een phishingsite dan op de legitieme website. Waarom is een goede vraag; zelf denk ik dat bijvoorbeeld de tijdsdruk een rol hierin speelt of dat er nog maar weinig modellen in voorraad zijn.
Daarnaast bleek dat er bij leeftijden onder de 18 en leeftijden boven 55 de security awareness op het gebied van het herkennen van phishingsites lager lag dan bij de andere groepen. Vanaf mijn generatie is de awareness het hoogst en deze loopt daarna geleidelijk af. Dit bewustzijn heb ik afgeleid van het aantal verschillen die gezien zijn tussen de twee websites. Deze heb ik ingedeeld in de eerder genoemde categorieën. Dus; help je buurmeisje, je neefje, je oma of je oom eens met het beter beveiligen van hun systeem. Zullen ze blij mee zijn!
Mocht je geïnspireerd zijn om hier zelf mee aan de slag te gaan, dan kun je de gebruikte scripts hier vinden of mijn presentatie hierover terugkijken:
 Phishing-analytics
Phishing-analytics
 Presentatie BSidesLV
Presentatie BSidesLV
Laat me vooral weten wanneer je toffe resultaten hebt!